Easy_SPH
Easy_SPH is a computational tool that solves the equations of fluid hydrodynamics using the smoothed-particle hydrodynamics (SPH) technique. Its main added value is the real-time visualisation of the system's evolution, which helps in understanding complex physical processes.
This method is used to study phenomena across a wide range of dynamic scales, from the formation of protoplanetary discs to the evolution of galaxies. Thanks to its modular design, the code offers great flexibility to adjust initial conditions and fluid parameters. It's possible to modify the equation of state, viscosity, gravitational potential, and boundary conditions.
As an example of its application, the following images show the evolution of a galactic gas disc. Starting from an initial gas cloud, the system gravitationally collapses, forming a rotationally supported structure, and finally settling into a stable disc.
 The code, written in C++, is highly optimised to leverage modern CPU architectures, achieving a performance of up to ~60 steps per second for systems with ~100,000 particles. This allows it to run on personal computers with low resources, making the tool accessible for exploring physical effects on planetary or galactic scales. The code, written in C++, is highly optimised to leverage modern CPU architectures, achieving a performance of up to ~60 steps per second for systems with ~100,000 particles. This allows it to run on personal computers with low resources, making the tool accessible for exploring physical effects on planetary or galactic scales.
Easy_SPH was developed by Bruno Celiz and Daniela Couriel as part of the Parallel Computing 2025 course, dictated by Nicolás Wolovick at FaMAF - UNC. The project is public and free and can be downloaded from its GitHub repository.
|
Machine model for The Generation of Catalogues of Eclipsing Binary System
 We present the Compound Decision Tree (CDT), an automatic tool for the generation of catalogues of eclipsing binary systems (EBs). This supervised machine learning model is part of a pipeline that has, as input, time series of EBs and, as output, the classification of these systems into Detached, Semi-detached and Contact. The training and evaluation of the model was performed using a catalogue of 100 EBs from VISTA Variables in the Via Lactea Survey (VVV) Survey, using tile d040. The performance of CDT to generate catalogues in other tiles was tested on tile d078, obtaining a good classification performance in the three types of EBs compared to the classification performed visually. Variables in the Vía Láctea Survey (VVV), utilizando la baldosa d040. El rendimiento de CDT para generar catálogos en otras baldosas se probó en la baldosa d078, obteniendo un buen rendimiento de clasificación en los tres tipos de EBs en comparación con la clasificación realizada visualmente. We present the Compound Decision Tree (CDT), an automatic tool for the generation of catalogues of eclipsing binary systems (EBs). This supervised machine learning model is part of a pipeline that has, as input, time series of EBs and, as output, the classification of these systems into Detached, Semi-detached and Contact. The training and evaluation of the model was performed using a catalogue of 100 EBs from VISTA Variables in the Via Lactea Survey (VVV) Survey, using tile d040. The performance of CDT to generate catalogues in other tiles was tested on tile d078, obtaining a good classification performance in the three types of EBs compared to the classification performed visually. Variables in the Vía Láctea Survey (VVV), utilizando la baldosa d040. El rendimiento de CDT para generar catálogos en otras baldosas se probó en la baldosa d078, obteniendo un buen rendimiento de clasificación en los tres tipos de EBs en comparación con la clasificación realizada visualmente.
During the process, characteristics were extracted from light curves with feets (feATURES eXTRACTOR for tIME sERIES, Cabral et al. 2018). Calculation of the amplitude difference between minima and different periods was added. After that, using MUTUAL INFORMATION, a ranking of 35 characteristics was produced. The score depends on the correlation between light curve characteristics and EBs.

Finally, we use 3 models (M1, M2 and M3). These models are composed of decision tree (DT), random forest (RF), k-nearest neighbour (KNN) and linear support vector classification (LSVC), plus a voting system. Classification is performed using a composite decision tree. First, M1 classifies BS C and D. Then, depending on the result, M2 classifies BS D and SD or M3 classifies BS C and SD.
In Automated classification of eclipsing binary systems in the VVV Survey the outline of the process for determining the best model for the classification of BEs is shown in detail. And in the repository of the vanedaza/CDTIn addition to a notebook for the use of the CDT model we include notebooks for data curation and pre-processing, feature generation, and a notebook is used to generate a report in .tex format containing the light curves of the eclipsing binary systems and a table with information about the system and the classification.
|
 ROGER: Reconstructing Orbits of Galaxies in ExtremeRegions using machine learning techniques ROGER: Reconstructing Orbits of Galaxies in ExtremeRegions using machine learning techniques
Galaxies in the Universe show a wide variety of properties as a result of the action of both, internal and environmental processes. Clusters of galaxies constitute the most extreme environments in the Universe for galaxy evolution. Galaxies in clusters exhibit different properties compared to galaxies that reside in the field, or in less massive systems.
On the other hand, machine learning techniques (machine learning) represent a new way of analyzing big data-sets in an agnostic and homogeneous way. Taking into account the amount of data generated by current and future surveys and simulations, the data-driven techniques will become a fundamental tool for their analysis.
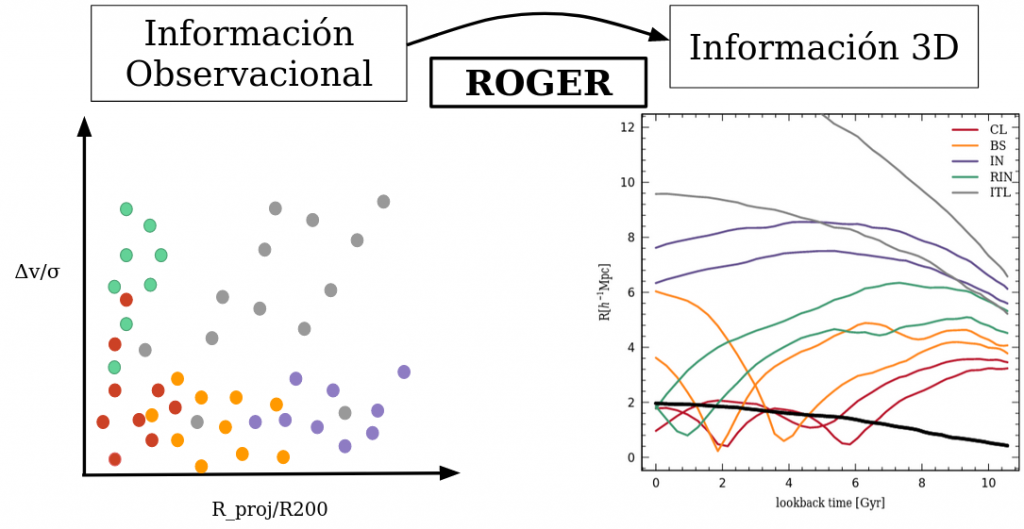
Here we present ROGER (Reconstructing Orbits of Galaxies in Extreme Regions), a machine learning technique that relates the two-dimensional PPSD position of galaxies to their 3D orbits. The code retrieves the probability for each galaxy to belong to each class using only its position on the projected phase-spacei.e, distance to the cluster center (normalized to R200) and relative LOS velocity to the cluster center (normalized to the velocity dispersion).
This code was trained and calibrated using a synthetic catalog of clusters and galaxies constructed using the semi-analytic model of galaxy formation and evolution SAG on the Multidark MDPL2 cosmological simulation.
ROGER is completely public and free. It can be used as an R package. For more details visit https://github.com/Martindelosrios/ROGERor its web page https://mdelosrios.shinyapps.io/roger_shiny/.
This project was developed by Martín de los Rios, Julián Martínez, Valeria Coenda, Hernán Muriel, Andrés Ruiz, Cristian Vega and Sofia Cora and was published in the international journal MNRAS.
|
MeSsI (Merging Systems Identification)
de los rios+16 2016MNRAS.458..226D
Merging galaxy systems provides observational evidence of the existence of dark matter and constraints on its properties. Therefore, statistical uniform samples of merging systems would be a powerful tool for several studies. In this work, we present MeSsI (Merging Systems Identification algorithm) a new machine learning method for merging systems identification.
We use as a starting point a mock catalog of galaxy systems, identified using traditional FoF algorithms, which experienced a major merger as indicated by its merger tree. This code is completely free and public and can be downloaded and used as an R package (https://github.com/Martindelosrios/MeSsI).
This project was developed by Martín de los Rios, Mariano Domínguez, Dante Paz and Manuel Merchán. |
Fargo 3D
 A versatile multifluid HD/MHD code that runs on clusters of CPUs or GPUs, with special emphasis on protoplanetary disks. he picture shows a hydrodynamical simulation of an interaction between two multiple planetary systems immersed in a gas disk. Multiple trails created by each planet are observed. Unlike simulations of an isolated planet, in a gaseous disk, a much more complex pattern is observed here as a result of perturbations between different bodies. Orbits of each planet are shown with white dashed lines. It is drawn, schematically, a representation of a mesh used to solve the problem in a computer. Simulation is carried out with the magnetohydrodynamic FARGO3D. The main features of FARGO3D are: FARGO3D son: A versatile multifluid HD/MHD code that runs on clusters of CPUs or GPUs, with special emphasis on protoplanetary disks. he picture shows a hydrodynamical simulation of an interaction between two multiple planetary systems immersed in a gas disk. Multiple trails created by each planet are observed. Unlike simulations of an isolated planet, in a gaseous disk, a much more complex pattern is observed here as a result of perturbations between different bodies. Orbits of each planet are shown with white dashed lines. It is drawn, schematically, a representation of a mesh used to solve the problem in a computer. Simulation is carried out with the magnetohydrodynamic FARGO3D. The main features of FARGO3D are: FARGO3D son:
- Cartesian, cylindrical or spherical geometry
- Calculations in 1, 2 or 3 dimensions.
- Orbital advection for HD and MHD calculations
- A simple Runge-Kutta N-body solver may be used to describe the orbital evolution of embedded point-like objects.
Multifluid capability. 1, 2 or 3 dimensional calculations. Orbital advection (aka FARGO) for HD and MHD calculations. No need to know CUDA: you can develop new functions in C and have them translated to CUDA automatically to run on GPUs.
FARGO3D was written by Pablo Benítez Llambay (main developper) and by Frédéric Masset. The multifluid version was developed by Pablo Benítez Llambay and Leonardo Krapp.
|
 This project presents a specialized library for time-domain astronomy, providing a collection of varied light-curve features to describe celestial objects through their luminosity changes. The library utilizes machine learning algorithms for classification, offering a collaborative and open tool designed to streamline the universal analysis of astronomical photometric databases. Its objectives include promoting standardization across surveys and enhancing efficiency in tasks such as modeling, classification, data cleaning, outlier detection, and overall data analysis. This project presents a specialized library for time-domain astronomy, providing a collection of varied light-curve features to describe celestial objects through their luminosity changes. The library utilizes machine learning algorithms for classification, offering a collaborative and open tool designed to streamline the universal analysis of astronomical photometric databases. Its objectives include promoting standardization across surveys and enhancing efficiency in tasks such as modeling, classification, data cleaning, outlier detection, and overall data analysis.
More information: feets
|

 Español de Argentina
Español de Argentina English
English


